What is Anomaly Detection?
Anomaly Detection is the identification of rare occurrences, items, or events of concern due to their differing characteristics from majority of the processed data. Anomalies, or outliers as they are also called, can represent security errors, structural defects, and even bank fraud or medical problems. There are three main forms of anomaly detection. The first type of anomaly detection is unsupervised anomaly detection. This technique detects anomalies in an unlabeled data set by comparing data points to each other, establishing a baseline "normal" outline for the data, and looking for differences between the points. In contrast, supervised anomaly detection requires a data set to be trained with specific "normal" and "abnormal" labels. Lastly, a semi-supervised anomaly detection technique requires a classifier to be trained on a "normal" set of data to establish a preset, and then analyzes the intended data to detect for anomalies. In essence, this technique allows the classifier to create the label.
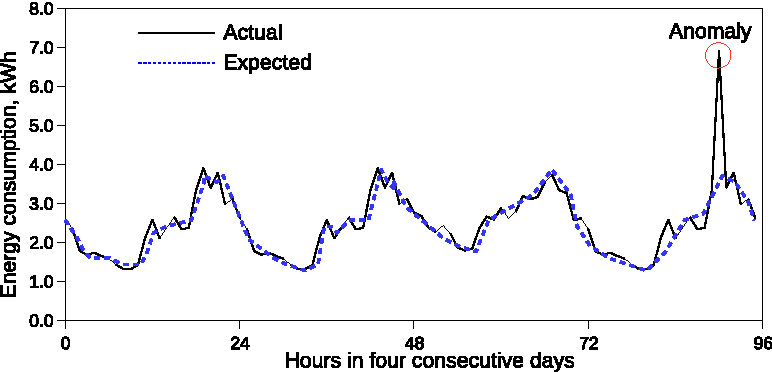
Anomaly Detection Techniques
There are many popular techniques for anomaly detection. An example of an alternative form of anomaly detection is called cluster analysis. Cluster analysis is the technique of analyzing data for bursts of activity, rather than specific rare objects. Other anomaly detection techniques, especially unsupervised processes, will fail if tasked with this form of anomaly detection. Other techniques include Bayesian Networks, Hidden Markov Models, and one-class support vector machines.
Applications of Anomaly Detection
Anomaly detection is used in applications such as fraud and intrusion detection, system health monitoring, and ecosystem disturbance monitoring. For example, in fraud detection, a bank can analyze a series of transaction data to monitor and detect for possible instances of fraud. In ecosystem disturbance monitoring, natural environment data is analyzed for anomalies that can help improve processes like earthquake and tsunami detection.

The image above represents anomaly detection. Note the red stars indicating rare objects and likely anomalies.
Anomaly Detection and Machine Learning
As discussed above, the various techniques for anomaly detection rely of forms of machine learning. As a classifier is trained to understand and label data, it improves its accuracy. Anomaly detection is often used in preprocessing as a way of removing anomalous data from the data set. In supervised learning situations, removing the anomalous data usually results in a statistically significant increase in accuracy.